Hyperparameter Optimization with Weights & Biases
What is Hyperparameter Optimization?
In machine learning, hyperparameter optimization or tuning is the problem of choosing a set of optimal hyperparameters for a learning algorithm. A hyperparameter is a parameter whose value is used to control the learning process. By contrast, the values of other parameters (typically node weights) are learned.
Strategies
Several strategies can be used for performing optimization. The most simple one is manual tuning. One such example is using the Elbow Method for determining the number of clusters in k-nearest neighbors algorithm. On the other hand complex models, have dozens of hyperparameters, and combined with the fact that some of them are continuous, the size of the search space explodes, so the manual effort. To tackle this issue, several other "smarter" approaches exist. Some of them are:
- Grid search
- Random search
- Bayesian optimization
- Gradient-based optimization
- Evolutionary optimization
- Population-based
To get more familiar with how these approaches work and what are the differences between them, I encourage you to read these articles 7 Hyperparameter Optimization Techniques Every Data Scientist Should Know, How To Make Deep Learning Models That Don’t Suck or Hyperparameter Optimization Approaches .
Tooling
Several frameworks provide implementations of the approaches mentioned above. In this tutorial, we are going to explore Weights & Biases - Sweeps, (WANDB for short).
Setup
For this tutorial, we are going to build a classifier for the Heart Disease UCI dataset. We will use RandomForestClassifier from sklearn to predict the presence of heart disease.
This tutorial does not focus on data pre-processing, so we'll dive straight into splitting the data into train and test data, and train the model once with default values for hyperparameters.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv('data\heart.csv')
X = df.drop(['target'], axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Train the model
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
and that's it, now we have successfully trained a random forest classifier with default values for its hyperparameters. This classifier has the following hyperparameters:
- bootstrap
- max_depth
- max_features
- min_samples_leaf
- min_samples_split
- n_estimators
Now let's get into setting up the optimization:
Optimization
Step 1: Define the training script
For more details, see the docs.
This script should serve as the main entry point for optimization. It performs one training and evaluation of the model with values for the hyperparameters injected from outside (through wandb.config).
It gets the configuration from the outside and performs training and evaluation of the model with fixed values for all of the hyperparameters. The name could be arbitrary, and for this example is train.py.
import wandb
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
WANDB_PROJECT_NAME = "hyperparameter-optimization"
with wandb.init(project=WANDB_PROJECT_NAME):
df = pd.read_csv('data\heart.csv')
X = df.drop(['target'], axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
config = wandb.config
rfc = RandomForestClassifier(
bootstrap=config.bootstrap,
max_depth = config.max_depth,
max_features = config.max_features,
min_samples_leaf = config.min_samples_leaf,
min_samples_split = config.min_samples_split,
n_estimators = config.n_estimators,
)
rfc.fit(X_train, y_train)
y_pred = rfc.predict(X_test)
wandb.log({'accuracy': accuracy_score(y_test, y_pred)})
Step 2: Define the optimization strategy and configuration
To determine the optimization strategy, i.e. which approach to be used for optimization, what values or ranges should be tried for every hyper-parameter, and what objective to be optimized, a configuration file sweep.yml needs to be defined.
This file contains some additional configuration regarding the python path, training script path (from Step 1), to get more familiar see the docs.
For this example the sweep.yml file is.
program: train.py
method: bayes
project: hyperparameter-optimization
command:
- ${env}
- ~/envs/hyperopt/bin/python
- ${program}
- ${args}
metric:
name: accuracy
goal: maximize
parameters:
bootstrap:
values: [True, False]
max_depth:
values: [2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, None]
max_features:
values: ['auto', 'sqrt']
min_samples_leaf:
values: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
min_samples_split:
values: [2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
n_estimators:
values: [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200, 300, 500]
Interpretation is that the training script is located at train.py, Bayesian optimization is going to be used and for bootstrap the values True and `False is going to be tried, for max_depth [2, 3, 4, .... ] and similarly for all of the hyperparameters. The objective is maximizing accuracy. So in other words, we want to assign values to the hyperparameters such that the accuracy is maximized.
Step 3: Initializing and Running the optimization
To start optimization, open a shell (with your favorite terminal emulator).
- Activate the python virtual environment (for UNIX
source ~/envs/hyperopt/bin/python, for other see the official Python guide.) Initialize the sweep
wandb sweep .\sweep.ymlExpected Output:

Run the sweep
wandb agent aleksandar1932/hyperparameter-optimization/r3s5xf4dExpected Output:

And that's it, now the running sweep can be observed at WANDB.
Step 4: Monitoring
Go to the sweep URL, from your shell output. For this example, the output is available here, and bellow.
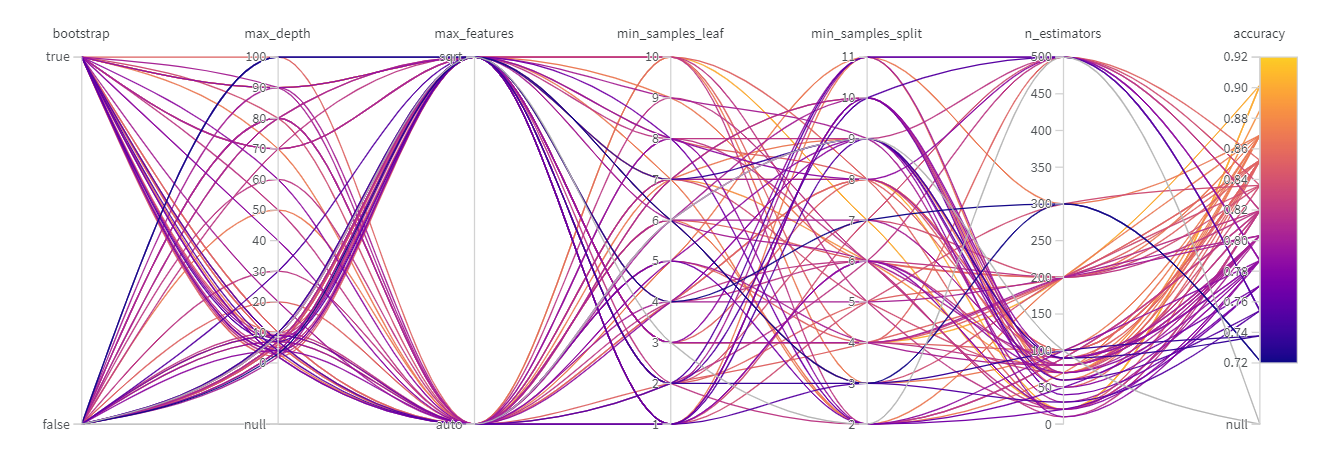
As the model is trained for different combinations for the hyperparameters, the results are updated in real-time. We can wait for the given approach to find the combination of values that when used for training, provide the best model, or stop the optimization either by terminating the running shell or through WANDB.
Conclusion
This sweep, performed 79 runs, and the best model scored 0.9016 accuracy on a randomly sampled test set for that particular run. (In train.py train_test_split is done for every run)
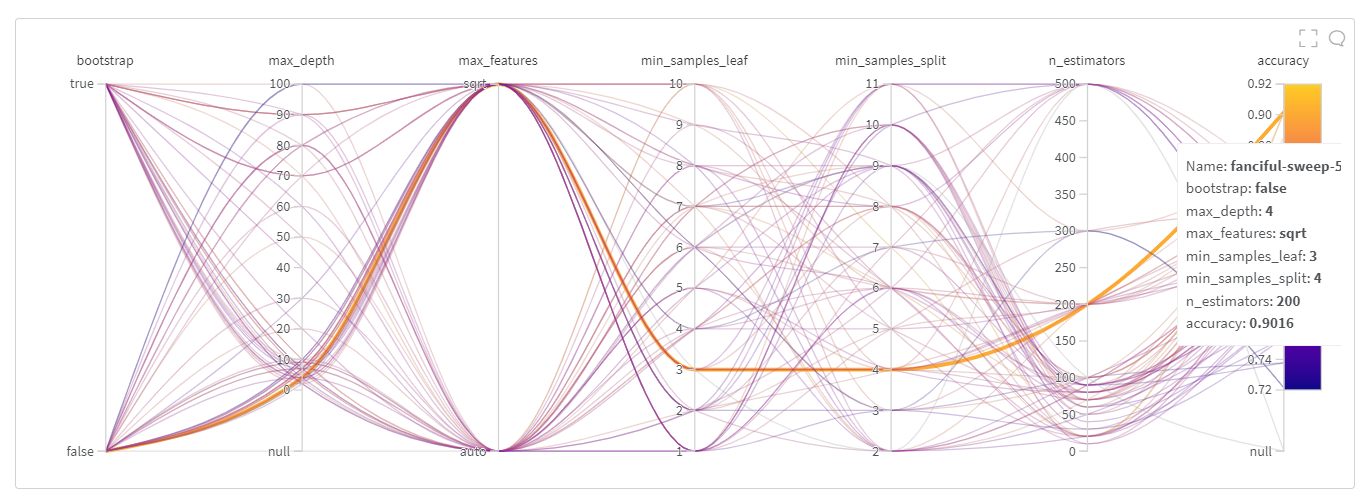
So, it can be concluded that the best RandomForestClassifier should be instantiated with the following hyperparameters.
model = RandomForestClassifier(
bootstrap=False,
max_depth = 4,
max_features = 'sqrt',
min_samples_leaf = 3,
min_samples_split = 4,
n_estimators = 200,
)
The code from this tutorial is available on GitHub.